
Tea Time Theme Time Term Matching
A quick code snippet to find matching terms between song lyrics
I love BBC 6 Music. On my morning train rides into LA I like to listen to the Radcliffe and Maconie Show. The hosts play a game at the end of their show where they play three tracks and ask listeners to guess what connects all three tracks.
I have yet to win this game which has prompted me to try to see if I can gain an advantage by analyzing some data about the the themes submitted. I have noticed that since the start of 2018, the theme relies on an exact term or phrase match among the lyrics 17% of the time.
library(tidyverse)
# read in the data
t <- read_csv("https://raw.githubusercontent.com/michaelpawlus/michaelpawlus.github.io/master/images/tttt1.csv")## Parsed with column specification:
## cols(
## index = col_integer(),
## date = col_character(),
## day = col_integer(),
## month = col_integer(),
## year = col_integer(),
## submitter = col_character(),
## submitter_city = col_character(),
## country = col_character(),
## Link = col_character(),
## link_location = col_character(),
## link_type = col_character(),
## col = col_character(),
## artist = col_character(),
## song = col_character()
## )# filter to one link per row, removing song 2 and 3
tr <- t %>% filter(col == "sa1")
# filter to just the rows were links are based on a term or phrase in the lyrics
tl <- t %>% filter(link_type == "Term", link_location == "Lyrics", col == "sa1")
# plot the proportion of cases were the link is a term or phrase in the lyrics
t %>%
select(index, link_location, link_type, col) %>%
filter(col == "sa1") %>%
select(-col) %>%
ggplot(aes(link_type)) +
geom_bar(aes(fill = link_location)) +
annotate("text", x = 'Term', y = 5, label = paste0(round(nrow(tl)/nrow(tr),2)*100,"%"), fontface = 2, size = 6) +
labs(y = NULL, x = "Link Type") +
guides(fill=guide_legend(title="Link Location"))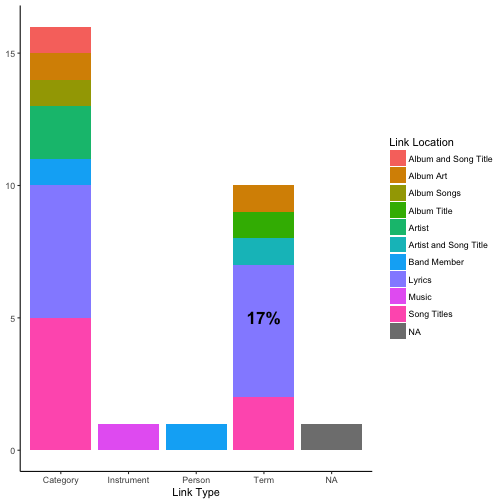
In these cases, these were the links.
tl %>% select(Link)## # A tibble: 5 x 1
## Link
## <chr>
## 1 "All songs contain \"Joan of Arc\" in the lyrics"
## 2 A reference to 4 AM in the lyrics
## 3 "All songs begin with phrase \"I was born\""
## 4 "All lyrics include phrase \"Shut your mouth\""
## 5 "All lyrics contain the phrase \"She's gone to stay\""Using what I have recently learned from the excellent Tidy Text Mining and really helpful package that pulls in lyrics from the site Genius, I was able to write a really quick script to get the lyrics for two songs and look for common terms between them. Here is an example to find one of the links above:
library(tidytext)
library(geniusR)
song1 <- genius_lyrics(artist = "Bill Withers", song = "Ain't No Sunshine") %>%
unnest_tokens(trigram, text, token = "ngrams", n = 3) %>%
separate(trigram, c("word1", "word2", "word3"), sep = " ") %>%
count(word1, word2, word3, sort = TRUE)
song2 <- genius_lyrics(artist = "Prince", song = "I Could Never Take The Place of Your Man") %>%
unnest_tokens(trigram, text, token = "ngrams", n = 3) %>%
separate(trigram, c("word1", "word2", "word3"), sep = " ") %>%
count(word1, word2, word3, sort = TRUE)
song1 %>%
inner_join(song2, by = c("word1","word2","word3")) %>%
count(word1, word2, word3, sort = TRUE)## # A tibble: 2 x 4
## word1 word2 word3 n
## <chr> <chr> <chr> <int>
## 1 and i know 1
## 2 gone to stay 1My next steps is to wrap this all in a function and add a check that first looks for matching trigrams and then finding none looks for bigrams and failing that lists all matching terms ommitting stop words. I will post that update soon.
As of this post, I still have yet to win Tea Time Theme Time (#TTTT)